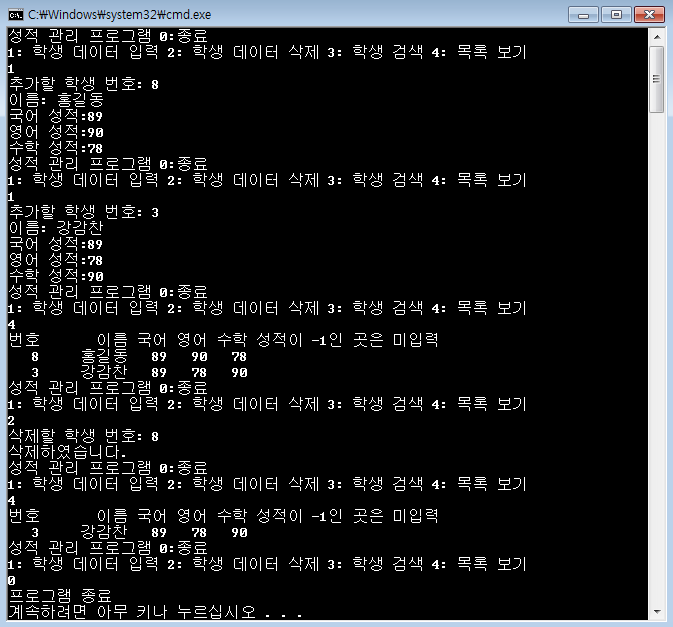
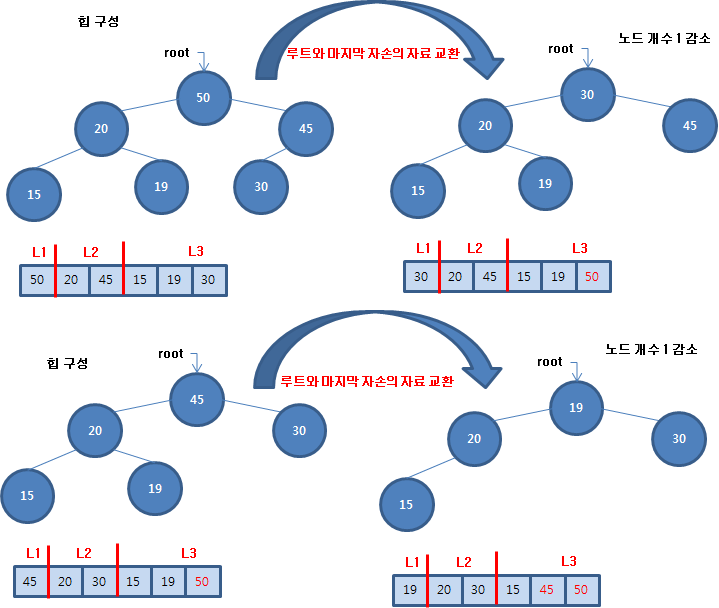
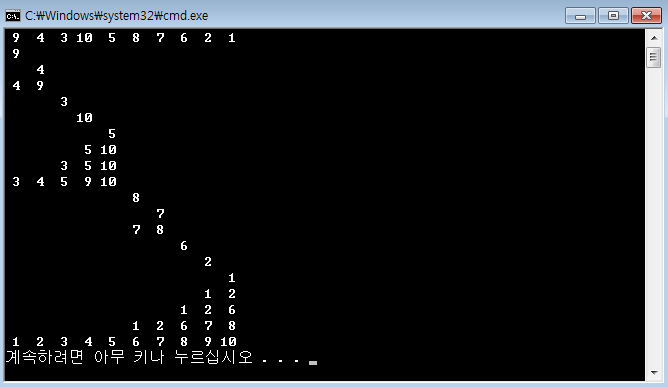
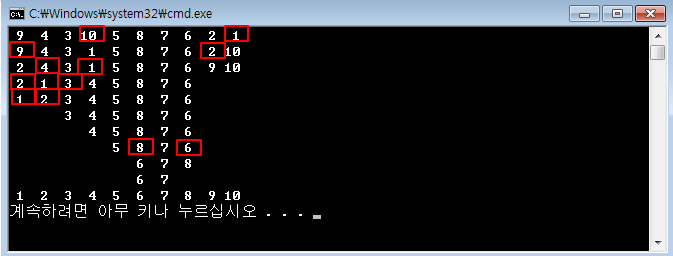
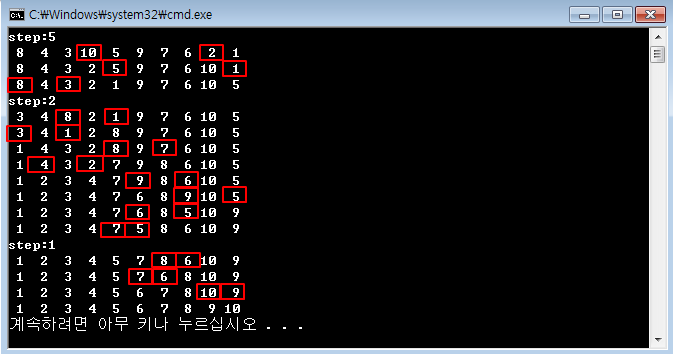
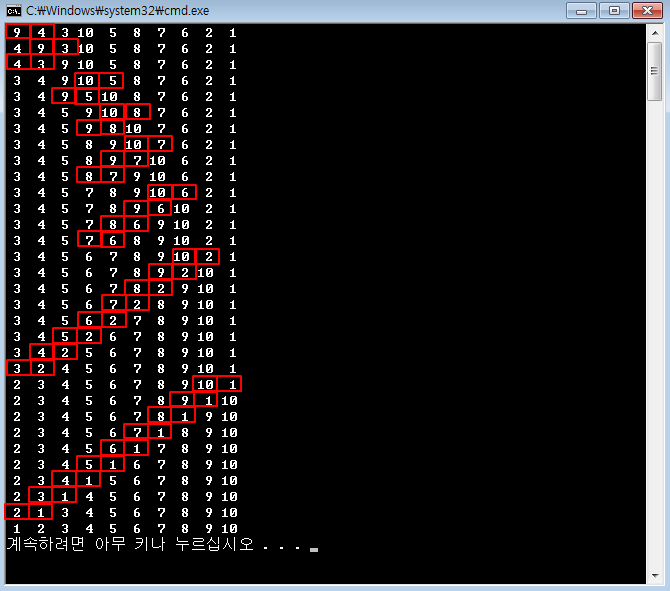
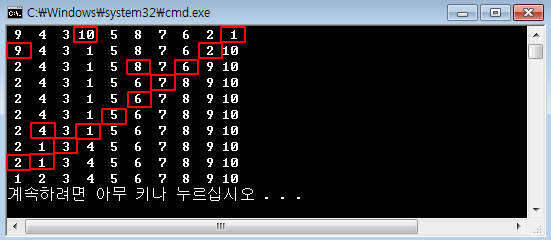
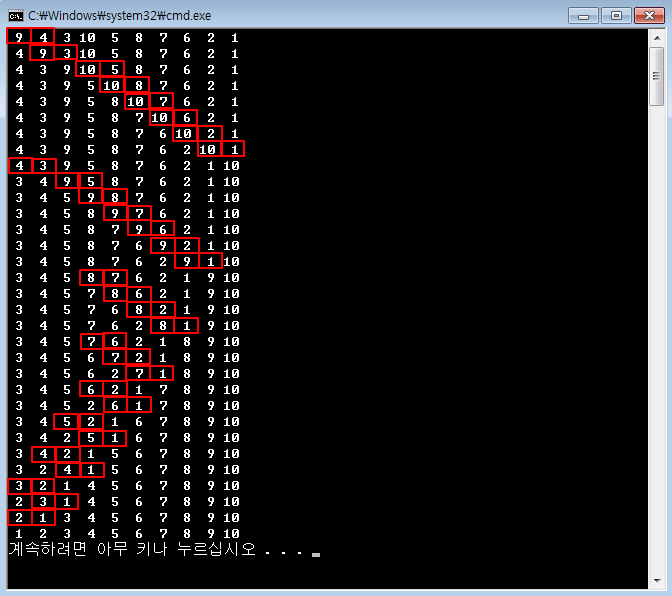
제어문을 이해하기 위해 별 출력을 요구할 때가 많죠.[C언어 소스] 역삼각형 출력[C언어 소스] 정사각형 출력 - 반복문 연습[C언어 소스] 삼각형 출력 - 반복문 연습[C언어 소스] 역삼각형 출력[C언어 소스] 다이아몬드 출력[C언어 소스] 산봉우리 출력[C언어 소스] 속이 빈 삼각형 출력 날짜 관련 처리도 많이 요구합니다.[C언어 소스] 년도와 일수 입력받아 시각 출력[C언어 소스] 1월 1일 요일 입력받아 달력 출력100분의 1초 단위로 현재 시각을 출력, C언어 소스difftimemktimetimeasctimeasctime_sctimectime_sgmtimegmtime_slocaltimelocaltime_sstrftime 문자열 관련은 필수죠.strlenstrcpystrcpy_sstrncpystr..