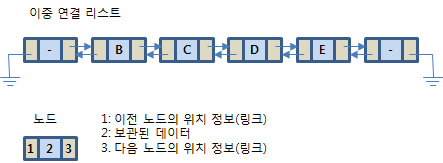
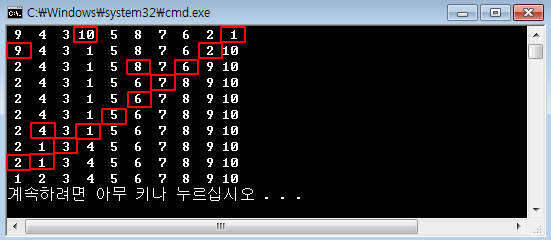
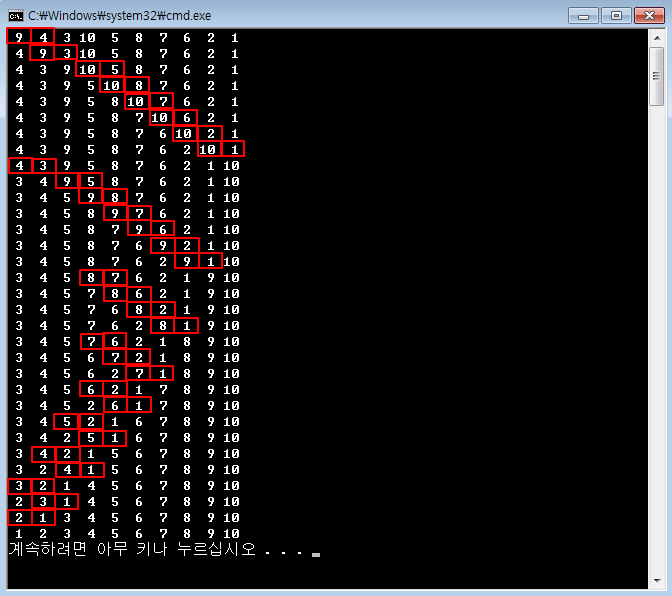
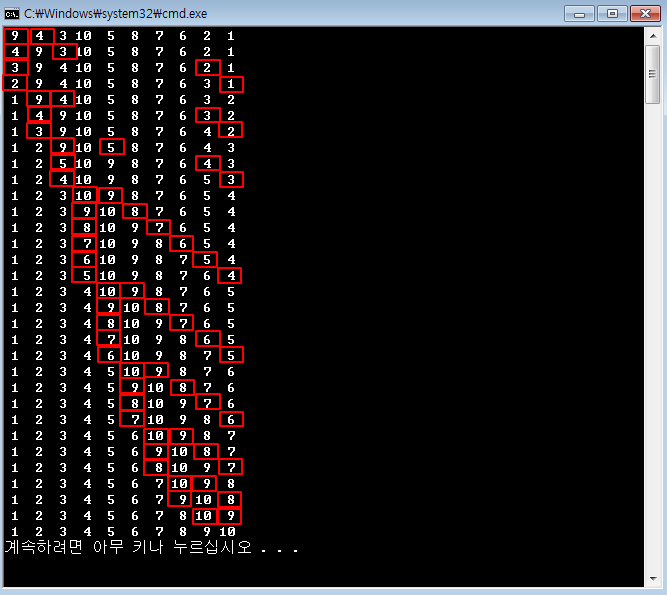
5.2.3 연결리스트 테스트 연결리스트를 사용하는 방법은 순차적으로 보관하거나 원하는 위치를 찾아 보관하는 방법이 대표적입니다. 동적 배열에서는 이 외에도 인덱스를 사용하는 방법이 있었지만 연결리스트를 사용할 때는 이 방법은 사용하지 않습니다. 따라서 테스트 코드는 크게 순차 보관하는 시뮬레이션과 원하는 순서로 보관하는 예로 구성할게요. int main() { Simul_Seq(); Simul_Order(); return 0; } 먼저 순차적으로 보관하는 테스트 코드를 작성합시다. void Simul_Seq() { 먼저 연결리스트를 동적으로 생성합니다. LinkedList *linkedlist = New_LinkedList(); 그리고 도서 개체를 생성하여 연결리스트에 순차 보관합니다. 순차 보관할 때는..