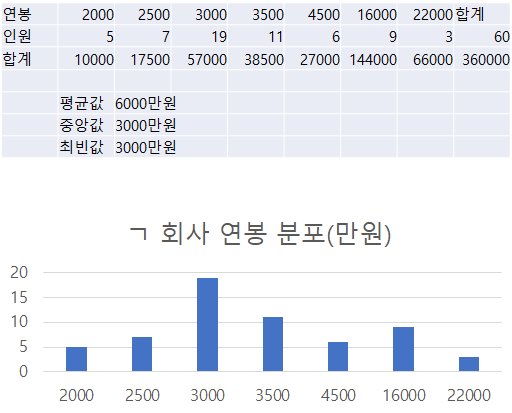
[4차 산업, 빅데이터 - 통계 실무활용] 평균으로 생기는 오해 줄이기 안녕하세요. 언제나 휴일, 언휴예요. 대푯값은 데이터 전체를 파악하기 위한 값으로 가장 많이 사용하는 것이 평균이다. 하지만 평균은 많은 오해를 가져오고 있습니다. 예를 들어 ㄱ 회사의 평균 연봉이 6000만원이라고 하였을 때 보통 6000만원은 받는 것으로 생각할 수 있습니다. 하지만 2000만원을 받는 직원이 5명 2500만원을 받는 직원이 7명, 3000만원을 받는 직원이 19명, 3500만원을 받는 직원이 11명, 4500만원을 받는 직원이 6명, 1억 6000만원을 받는 임원이 9명, 2억 2000만원을 받는 임원이 3명이라고 한다면 6000만원보다 적게 받는 인원이 48명이고 6000만원보다 많게 받는 인원이 12명입니다.