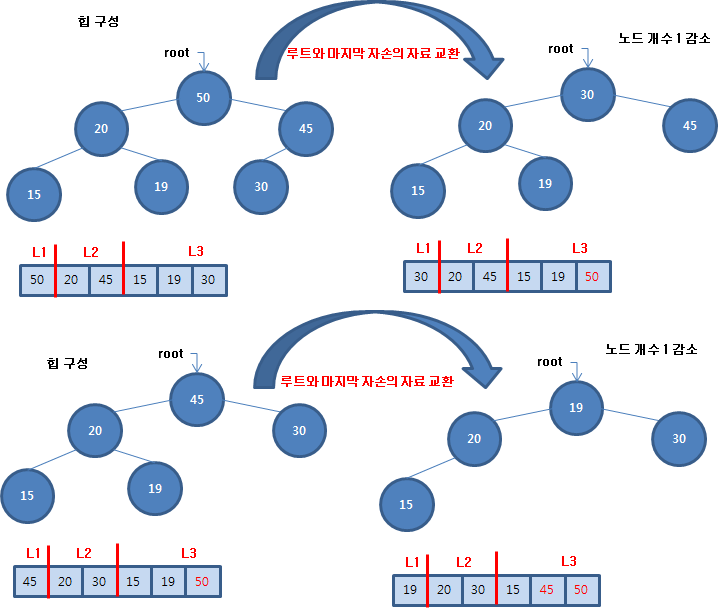
선형 자료구조에 보관한 자료 중에 최소값을 찾는 방법은 많습니다. 그 중에 분할 정복 알고리즘으로 해결하는 방법을 알아봅시다. 분할 정복 알고리즘에서는 모집합을 부분 집합으로 나누는 작업을 선행합니다. 원하는 기준에 맞게 부분 집합으로 분리한 후에 부분 집합에서 원하는 결과를 구합니다. 그리고 해결한 부분을 합쳐서 다시 커다란 집합에서 원하는 결과를 구하는 과정을 반복합니다. 최소값(최대값) 찾기 알고리즘도 분할 정복 알고리즘으로 문제를 해결할 수 있습니다. 배열의 원소 중에 최소값을 찾기 위해 원소 개수가 2보다 크면 배열의 앞 부분에서 최소값을 찾기 위해 재귀함수를 호출하고 마찬가지로 뒷 부분에서 최소값을 찾기 위해 재귀함수를 호출합니다. 그리고 배열의 앞 부분의 최소값과 뒷 부분의 최소값을 비교하여..