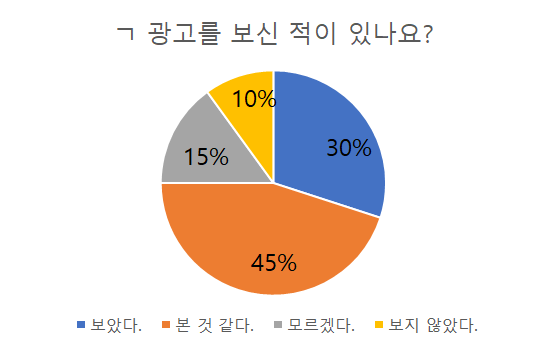
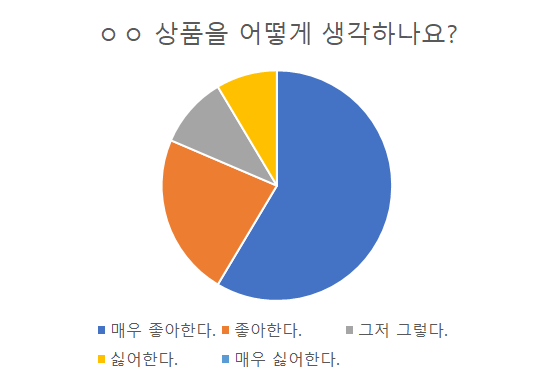
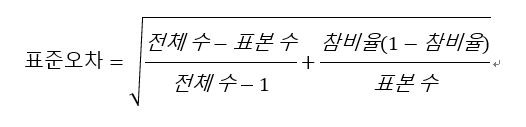
[4차 산업, 빅데이터] 다중회귀분석과 로지스틱회귀분석 안녕하세요. 언제나 휴일, 언휴예요. 다중회귀분석(Multiple linear regression analysis)은 예측하고 싶은 결과에 영향을 주는 인자가 여러 개 있는 상황으로 확장시킨 회귀 분석입니다. 즉, 종속변수를 설명하는 독립변수가 2개 이상일 때 이들의 관련성을 알고 이를 반영하는 방정식(Y = B0 + B1X1 + B2X2 + B3X3 ... + BnXn)을 구할 때 사용합니다. (참고: cbgSTAT 통계분석 생존지침서) 그리고 로지스틱회귀분석(logistic regression analysis)은 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측할 때 사용하는 통계 기법입니다. (참고: 위키백과 로지스틱 회귀) 이러한 ..